CHAID and caret -- a good combination
In an earlier post I focused on an in
depth visit with CHAID (Chi-square automatic interaction detection). There are
lots of tools that can help you predict an outcome, or classify, but CHAID is
especially good at helping you explain to any audience how the model arrives
at it’s prediction or classification. It’s also incredibly robust from a
statistical perspective, making almost no assumptions about your data for
distribution or normality. This post I’ll focus on marrying CHAID with the
awesome caret package to make our
predicting easier and hopefully more accurate. Although not strictly necessary
you’re probably best served by reading the original post first.
We’ve been using a dataset that comes to us from the
IBM Watson Project
and comes packaged with the rsample library. It’s a very practical and
understandable dataset. A great use case for a tree based algorithm. Imagine
yourself in a fictional company faced with the task of trying to figure out
which employees you are going to “lose” a.k.a. attrition or turnover. There’s a
steep cost involved in keeping good employees, and training and on-boarding can
be expensive. Being able to predict attrition even a little bit better would
save you lots of money and make the company better, especially if you can
understand exactly what you have to “watch out for” that might indicate the
person is a high risk to leave.
Setup and library loading
If you’ve never used CHAID before you may also not have partykit. CHAID
isn’t on CRAN but I have commented out the install command below. You’ll also
get a variety of messages, none of which is relevant to this example so I’ve
suppressed them.
# install.packages("partykit")
# install.packages("CHAID", repos="http://R-Forge.R-project.org")
require(modeldata) # for dataset
require(rsample) # for splitting also loads broom and tidyr
require(dplyr)
require(CHAID)
require(purrr) # we'll use it to consolidate some data
require(caret)
require(kableExtra) # just to make the output nicerPredicting attrition in a fictional company
Last time
I spent a great deal of time explaining the mechanics of loading the data. This
time we’ll race right through. If you need an explanation of what’s going on
please refer back. I’ve embedded some comments in the code to follow along and
changing the data frame name to newattrit is not strictly necessary it just
mimics the last post.
data(attrition)
str(attrition) # included in modeldata## 'data.frame': 1470 obs. of 31 variables:
## $ Age : int 41 49 37 33 27 32 59 30 38 36 ...
## $ Attrition : Factor w/ 2 levels "No","Yes": 2 1 2 1 1 1 1 1 1 1 ...
## $ BusinessTravel : Factor w/ 3 levels "Non-Travel","Travel_Frequently",..: 3 2 3 2 3 2 3 3 2 3 ...
## $ DailyRate : int 1102 279 1373 1392 591 1005 1324 1358 216 1299 ...
## $ Department : Factor w/ 3 levels "Human_Resources",..: 3 2 2 2 2 2 2 2 2 2 ...
## $ DistanceFromHome : int 1 8 2 3 2 2 3 24 23 27 ...
## $ Education : Ord.factor w/ 5 levels "Below_College"<..: 2 1 2 4 1 2 3 1 3 3 ...
## $ EducationField : Factor w/ 6 levels "Human_Resources",..: 2 2 5 2 4 2 4 2 2 4 ...
## $ EnvironmentSatisfaction : Ord.factor w/ 4 levels "Low"<"Medium"<..: 2 3 4 4 1 4 3 4 4 3 ...
## $ Gender : Factor w/ 2 levels "Female","Male": 1 2 2 1 2 2 1 2 2 2 ...
## $ HourlyRate : int 94 61 92 56 40 79 81 67 44 94 ...
## $ JobInvolvement : Ord.factor w/ 4 levels "Low"<"Medium"<..: 3 2 2 3 3 3 4 3 2 3 ...
## $ JobLevel : int 2 2 1 1 1 1 1 1 3 2 ...
## $ JobRole : Factor w/ 9 levels "Healthcare_Representative",..: 8 7 3 7 3 3 3 3 5 1 ...
## $ JobSatisfaction : Ord.factor w/ 4 levels "Low"<"Medium"<..: 4 2 3 3 2 4 1 3 3 3 ...
## $ MaritalStatus : Factor w/ 3 levels "Divorced","Married",..: 3 2 3 2 2 3 2 1 3 2 ...
## $ MonthlyIncome : int 5993 5130 2090 2909 3468 3068 2670 2693 9526 5237 ...
## $ MonthlyRate : int 19479 24907 2396 23159 16632 11864 9964 13335 8787 16577 ...
## $ NumCompaniesWorked : int 8 1 6 1 9 0 4 1 0 6 ...
## $ OverTime : Factor w/ 2 levels "No","Yes": 2 1 2 2 1 1 2 1 1 1 ...
## $ PercentSalaryHike : int 11 23 15 11 12 13 20 22 21 13 ...
## $ PerformanceRating : Ord.factor w/ 4 levels "Low"<"Good"<"Excellent"<..: 3 4 3 3 3 3 4 4 4 3 ...
## $ RelationshipSatisfaction: Ord.factor w/ 4 levels "Low"<"Medium"<..: 1 4 2 3 4 3 1 2 2 2 ...
## $ StockOptionLevel : int 0 1 0 0 1 0 3 1 0 2 ...
## $ TotalWorkingYears : int 8 10 7 8 6 8 12 1 10 17 ...
## $ TrainingTimesLastYear : int 0 3 3 3 3 2 3 2 2 3 ...
## $ WorkLifeBalance : Ord.factor w/ 4 levels "Bad"<"Good"<"Better"<..: 1 3 3 3 3 2 2 3 3 2 ...
## $ YearsAtCompany : int 6 10 0 8 2 7 1 1 9 7 ...
## $ YearsInCurrentRole : int 4 7 0 7 2 7 0 0 7 7 ...
## $ YearsSinceLastPromotion : int 0 1 0 3 2 3 0 0 1 7 ...
## $ YearsWithCurrManager : int 5 7 0 0 2 6 0 0 8 7 ...# the easy to convert because they are integers with less than 10 levels
attrition <- attrition %>%
mutate_if(function(col) length(unique(col)) <= 10 & is.integer(col), as.factor)
# More difficult to get 5 levels
attrition$YearsSinceLastPromotion <- cut(
attrition$YearsSinceLastPromotion,
breaks = c(-1, 0.9, 1.9, 2.9, 30),
labels = c("Less than 1", "1", "2", "More than 2")
)
# everything else just five more or less even levels
attrition <- attrition %>%
mutate_if(is.numeric, funs(cut_number(., n=5)))## Warning: `funs()` is deprecated as of dplyr 0.8.0.
## Please use a list of either functions or lambdas:
##
## # Simple named list:
## list(mean = mean, median = median)
##
## # Auto named with `tibble::lst()`:
## tibble::lst(mean, median)
##
## # Using lambdas
## list(~ mean(., trim = .2), ~ median(., na.rm = TRUE))
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_warnings()` to see where this warning was generated.dim(attrition)## [1] 1470 31str(attrition) ## 'data.frame': 1470 obs. of 31 variables:
## $ Age : Factor w/ 5 levels "[18,29]","(29,34]",..: 4 5 3 2 1 2 5 2 3 3 ...
## $ Attrition : Factor w/ 2 levels "No","Yes": 2 1 2 1 1 1 1 1 1 1 ...
## $ BusinessTravel : Factor w/ 3 levels "Non-Travel","Travel_Frequently",..: 3 2 3 2 3 2 3 3 2 3 ...
## $ DailyRate : Factor w/ 5 levels "[102,392]","(392,656]",..: 4 1 5 5 2 4 5 5 1 5 ...
## $ Department : Factor w/ 3 levels "Human_Resources",..: 3 2 2 2 2 2 2 2 2 2 ...
## $ DistanceFromHome : Factor w/ 5 levels "[1,2]","(2,5]",..: 1 3 1 2 1 1 2 5 5 5 ...
## $ Education : Ord.factor w/ 5 levels "Below_College"<..: 2 1 2 4 1 2 3 1 3 3 ...
## $ EducationField : Factor w/ 6 levels "Human_Resources",..: 2 2 5 2 4 2 4 2 2 4 ...
## $ EnvironmentSatisfaction : Ord.factor w/ 4 levels "Low"<"Medium"<..: 2 3 4 4 1 4 3 4 4 3 ...
## $ Gender : Factor w/ 2 levels "Female","Male": 1 2 2 1 2 2 1 2 2 2 ...
## $ HourlyRate : Factor w/ 5 levels "[30,45]","(45,59]",..: 5 3 5 2 1 4 4 3 1 5 ...
## $ JobInvolvement : Ord.factor w/ 4 levels "Low"<"Medium"<..: 3 2 2 3 3 3 4 3 2 3 ...
## $ JobLevel : Factor w/ 5 levels "1","2","3","4",..: 2 2 1 1 1 1 1 1 3 2 ...
## $ JobRole : Factor w/ 9 levels "Healthcare_Representative",..: 8 7 3 7 3 3 3 3 5 1 ...
## $ JobSatisfaction : Ord.factor w/ 4 levels "Low"<"Medium"<..: 4 2 3 3 2 4 1 3 3 3 ...
## $ MaritalStatus : Factor w/ 3 levels "Divorced","Married",..: 3 2 3 2 2 3 2 1 3 2 ...
## $ MonthlyIncome : Factor w/ 5 levels "[1.01e+03,2.7e+03]",..: 4 3 1 2 2 2 1 1 4 3 ...
## $ MonthlyRate : Factor w/ 5 levels "[2.09e+03,6.89e+03]",..: 4 5 1 5 3 3 2 3 2 3 ...
## $ NumCompaniesWorked : Factor w/ 10 levels "0","1","2","3",..: 9 2 7 2 10 1 5 2 1 7 ...
## $ OverTime : Factor w/ 2 levels "No","Yes": 2 1 2 2 1 1 2 1 1 1 ...
## $ PercentSalaryHike : Factor w/ 5 levels "[11,12]","(12,13]",..: 1 5 3 1 1 2 5 5 5 2 ...
## $ PerformanceRating : Ord.factor w/ 4 levels "Low"<"Good"<"Excellent"<..: 3 4 3 3 3 3 4 4 4 3 ...
## $ RelationshipSatisfaction: Ord.factor w/ 4 levels "Low"<"Medium"<..: 1 4 2 3 4 3 1 2 2 2 ...
## $ StockOptionLevel : Factor w/ 4 levels "0","1","2","3": 1 2 1 1 2 1 4 2 1 3 ...
## $ TotalWorkingYears : Factor w/ 5 levels "[0,5]","(5,8]",..: 2 3 2 2 2 2 4 1 3 4 ...
## $ TrainingTimesLastYear : Factor w/ 7 levels "0","1","2","3",..: 1 4 4 4 4 3 4 3 3 4 ...
## $ WorkLifeBalance : Ord.factor w/ 4 levels "Bad"<"Good"<"Better"<..: 1 3 3 3 3 2 2 3 3 2 ...
## $ YearsAtCompany : Factor w/ 5 levels "[0,2]","(2,5]",..: 3 4 1 4 1 3 1 1 4 3 ...
## $ YearsInCurrentRole : Factor w/ 5 levels "[0,1]","(1,2]",..: 3 4 1 4 2 4 1 1 4 4 ...
## $ YearsSinceLastPromotion : Factor w/ 4 levels "Less than 1",..: 1 2 1 4 3 4 1 1 2 4 ...
## $ YearsWithCurrManager : Factor w/ 5 levels "[0,1]","(1,2]",..: 4 4 1 1 2 4 1 1 5 4 ...newattrit <- attrition %>%
select_if(is.factor)
dim(newattrit)## [1] 1470 31Okay we have data on 1,470 employees. We have 30 potential predictor (features)
or independent variables and the all important attrition variable which gives
us a yes or no answer to the question of whether or not the employee left. We’re
to build the most accurate predictive model we can that is also simple
(parsimonious) and explainable. The predictors we have seem to be the sorts of
data we might have on hand in our HR files and thank goodness are labelled in a
way that makes them pretty self explanatory.
Last post we explored the control options and built predictive models like the one below. For a review of what the output means and how CHAID works please refer back.
# explore the control options
ctrl <- chaid_control(minsplit = 200, minprob = 0.05)
ctrl## $alpha2
## [1] 0.05
##
## $alpha3
## [1] -1
##
## $alpha4
## [1] 0.05
##
## $minsplit
## [1] 200
##
## $minbucket
## [1] 7
##
## $minprob
## [1] 0.05
##
## $stump
## [1] FALSE
##
## $maxheight
## [1] -1
##
## attr(,"class")
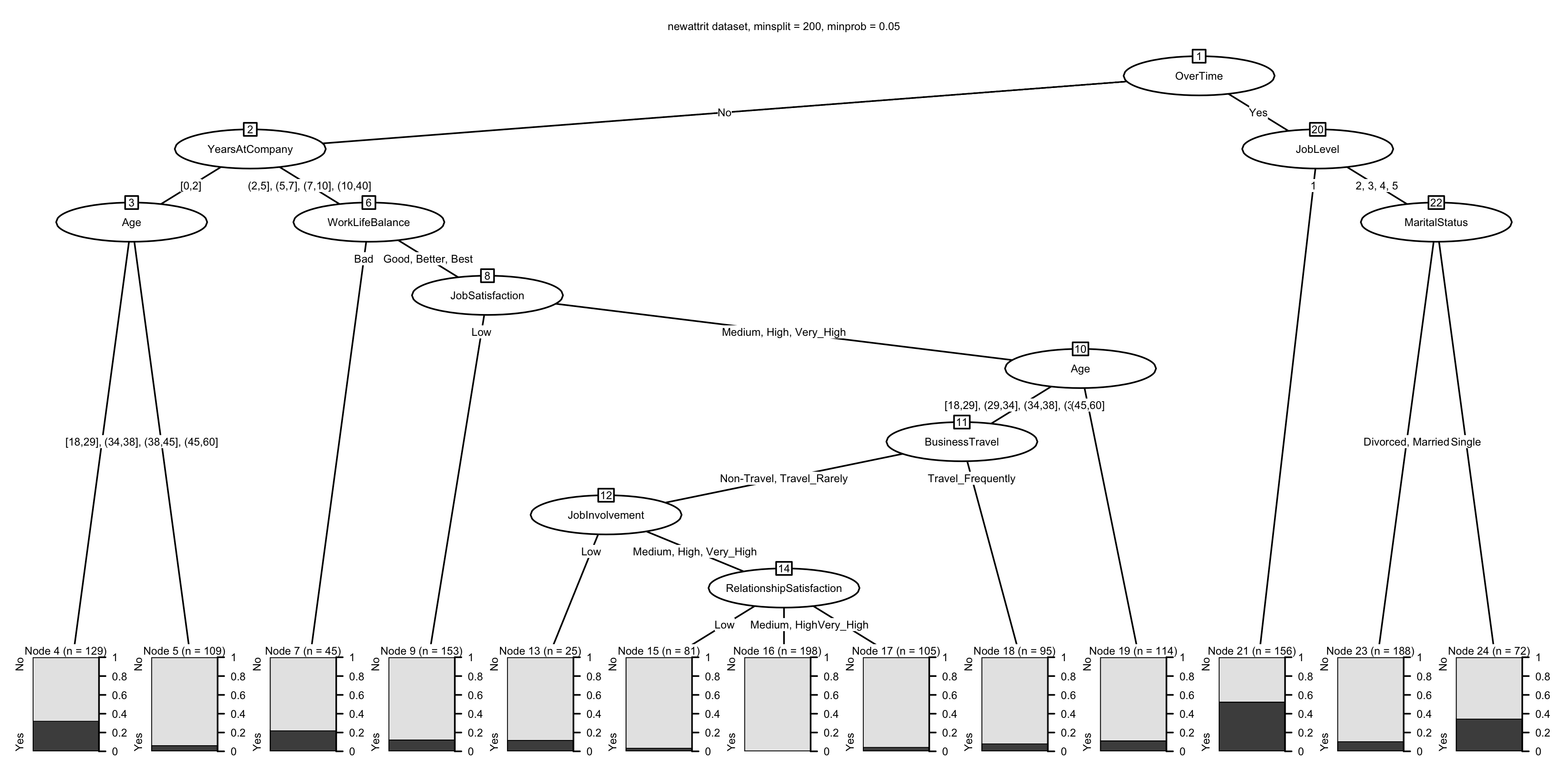
## [1] "chaid_control"full_data <- chaid(Attrition ~ ., data = newattrit, control = ctrl)
print(full_data)##
## Model formula:
## Attrition ~ Age + BusinessTravel + DailyRate + Department + DistanceFromHome +
## Education + EducationField + EnvironmentSatisfaction + Gender +
## HourlyRate + JobInvolvement + JobLevel + JobRole + JobSatisfaction +
## MaritalStatus + MonthlyIncome + MonthlyRate + NumCompaniesWorked +
## OverTime + PercentSalaryHike + PerformanceRating + RelationshipSatisfaction +
## StockOptionLevel + TotalWorkingYears + TrainingTimesLastYear +
## WorkLifeBalance + YearsAtCompany + YearsInCurrentRole + YearsSinceLastPromotion +
## YearsWithCurrManager
##
## Fitted party:
## [1] root
## | [2] OverTime in No
## | | [3] YearsAtCompany in [0,2]
## | | | [4] Age in [18,29], (29,34]: No (n = 129, err = 32.6%)
## | | | [5] Age in (34,38], (38,45], (45,60]: No (n = 109, err = 6.4%)
## | | [6] YearsAtCompany in (2,5], (5,7], (7,10], (10,40]
## | | | [7] WorkLifeBalance in Bad: No (n = 45, err = 22.2%)
## | | | [8] WorkLifeBalance in Good, Better, Best
## | | | | [9] JobSatisfaction in Low: No (n = 153, err = 12.4%)
## | | | | [10] JobSatisfaction in Medium, High, Very_High
## | | | | | [11] Age in [18,29], (29,34], (34,38], (38,45]
## | | | | | | [12] BusinessTravel in Non-Travel, Travel_Rarely
## | | | | | | | [13] JobInvolvement in Low: No (n = 25, err = 12.0%)
## | | | | | | | [14] JobInvolvement in Medium, High, Very_High
## | | | | | | | | [15] RelationshipSatisfaction in Low: No (n = 81, err = 3.7%)
## | | | | | | | | [16] RelationshipSatisfaction in Medium, High: No (n = 198, err = 0.0%)
## | | | | | | | | [17] RelationshipSatisfaction in Very_High: No (n = 105, err = 4.8%)
## | | | | | | [18] BusinessTravel in Travel_Frequently: No (n = 95, err = 8.4%)
## | | | | | [19] Age in (45,60]: No (n = 114, err = 11.4%)
## | [20] OverTime in Yes
## | | [21] JobLevel in 1: Yes (n = 156, err = 47.4%)
## | | [22] JobLevel in 2, 3, 4, 5
## | | | [23] MaritalStatus in Divorced, Married: No (n = 188, err = 10.6%)
## | | | [24] MaritalStatus in Single: No (n = 72, err = 34.7%)
##
## Number of inner nodes: 11
## Number of terminal nodes: 13plot(
full_data,
main = "newattrit dataset, minsplit = 200, minprob = 0.05",
gp = gpar(
lty = "solid",
lwd = 2,
fontsize = 10
)
)
Over-fitting
Okay we have a working predictive model. At this point, however, we’ve been
cheating to a certain degree! We’ve been using every available piece of data
we have to develop the best possible model. We’ve told the powerful all-knowing
algorithims to squeeze every last bit of accuracy they can out of the data.
We’ve told it to fit the best possible model. Problem is that we may have done
that at the cost of being able to generalize our model to new data or to new
situations. That’s the problem of over-fitting in a nutshell. If you want a
fuller understanding please consider
reading this post on EliteDataScience.
I’m going to move on to a solution for solving this limitation and that’s where caret comes in.
We’re going to use caret to employ cross-validation a.k.a. cv to solve this challenge for us, or more accurately to mitigate the problem. The same article explains it well so I won’t repeat that explanation here, I’ll simply show you how to run the steps in R.
This is also a good time to point out that caret has extraordinarily comprehensive documentation which I used extensively and I’m limiting myself to the basics.
As a first step, let’s just take 30% of our data and put is aside for a minute.
We’re not going to let chaid see it or know about it as we build the model. In
some scenarios you have subsequent data at hand for checking your model (data
from another company or another year or …). We don’t, so we’re going to
self-impose this restraint. Why 30%? Doesn’t have to be, could be as low as 20%
or as high as 40% it really depends on how conservative you want to be, and how
much data you have at hand. Since this is just a tutorial we’ll simply use 30%
as a representative number. We’ve already loaded both rsample and caret
either of which is quite capable of making this split for us. I’m arbitrarily
going to use rsample syntax which is the line with initial_split(newattrit, prop = .7, strata = "Attrition") in it. That takes our data set newattrit
makes a 70% split ensuring that we keep our outcome variable Attrition as
close to 70/30 as we can. This is important because our data is already pretty
lop-sided for outcomes. The two subsequent lines serve to take the data
contained in split and produce two separate dataframes, test and train.
They have 440 and 1030 staff members each. We’ll set test aside for now and
focus on train.
# Create training (70%) and test (30%) sets for the attrition data.
# Use set.seed for reproducibility
#####
set.seed(1234)
split <- initial_split(newattrit, prop = .7, strata = "Attrition")
train <- training(split)
test <- testing(split)The next step is a little counter-intuitive but quite practical. Turns out that
many models do not perform well when you feed them a formula for the model
even if they claim to support a formula interface (as CHAID does).
Here’s an SO link
that discusses in detail but my suggestion to you is to always separate them and
avoid the problem altogether. We’re just taking our predictors or features
and putting them in x while we put our outcome in y.
# create response and feature data
features <- setdiff(names(train), "Attrition")
x <- train[, features]
y <- train$AttritionAlright, let’s get back on track. trainControl is the function within caret
we need to use. Chapter 5 in the caret doco covers it in great detail. I’m
simply going to pluck out a few sane and safe options. method = "cv" gets us
cross-validation. number = 10 is pretty obvious. I happen to like seeing the
progress in case I want to go for coffee so verboseIter = TRUE, and I play it
safe and explicitly save my predictions savePredictions = "final". We put
everything in train_control which we’ll use in a minute.
# set up 10-fold cross validation procedure
train_control <- trainControl(method = "cv",
number = 10,
verboseIter = TRUE,
savePredictions = "final")Not surprisingly the train function in caret trains our model! It wants to
know what our x and y’s are, as well as our training control parameters
which we’ve parked in train_control. At this point we could successfully
unleash the dogs of war (sorry Shakespeare) and train our model since we know we
want to use chaid. But let’s change one other useful thing and that is
metric which is what metric we want to use to pick the “best” model. Instead
of the default “accuracy” we’ll use Kappa which as you may remember from the
last post is more conservative measure of how well we did.
If you’re running this code yourself this is a good time to take a coffee break. I’ll tell you later how to find out how long it took more or less exactly. But there’s no getting around it we’re model building many more times so it takes longer.
# train model
chaid.m1 <- train(
x = x,
y = y,
method = "chaid",
metric = "Kappa",
trControl = train_control
)## + Fold01: alpha2=0.05, alpha3=-1, alpha4=0.05
## - Fold01: alpha2=0.05, alpha3=-1, alpha4=0.05
## + Fold01: alpha2=0.03, alpha3=-1, alpha4=0.03
## - Fold01: alpha2=0.03, alpha3=-1, alpha4=0.03
## + Fold01: alpha2=0.01, alpha3=-1, alpha4=0.01
## - Fold01: alpha2=0.01, alpha3=-1, alpha4=0.01
## + Fold02: alpha2=0.05, alpha3=-1, alpha4=0.05
## - Fold02: alpha2=0.05, alpha3=-1, alpha4=0.05
## + Fold02: alpha2=0.03, alpha3=-1, alpha4=0.03
## - Fold02: alpha2=0.03, alpha3=-1, alpha4=0.03
## + Fold02: alpha2=0.01, alpha3=-1, alpha4=0.01
## - Fold02: alpha2=0.01, alpha3=-1, alpha4=0.01
## + Fold03: alpha2=0.05, alpha3=-1, alpha4=0.05
## - Fold03: alpha2=0.05, alpha3=-1, alpha4=0.05
## + Fold03: alpha2=0.03, alpha3=-1, alpha4=0.03
## - Fold03: alpha2=0.03, alpha3=-1, alpha4=0.03
## + Fold03: alpha2=0.01, alpha3=-1, alpha4=0.01
## - Fold03: alpha2=0.01, alpha3=-1, alpha4=0.01
## + Fold04: alpha2=0.05, alpha3=-1, alpha4=0.05
## - Fold04: alpha2=0.05, alpha3=-1, alpha4=0.05
## + Fold04: alpha2=0.03, alpha3=-1, alpha4=0.03
## - Fold04: alpha2=0.03, alpha3=-1, alpha4=0.03
## + Fold04: alpha2=0.01, alpha3=-1, alpha4=0.01
## - Fold04: alpha2=0.01, alpha3=-1, alpha4=0.01
## + Fold05: alpha2=0.05, alpha3=-1, alpha4=0.05
## - Fold05: alpha2=0.05, alpha3=-1, alpha4=0.05
## + Fold05: alpha2=0.03, alpha3=-1, alpha4=0.03
## - Fold05: alpha2=0.03, alpha3=-1, alpha4=0.03
## + Fold05: alpha2=0.01, alpha3=-1, alpha4=0.01
## - Fold05: alpha2=0.01, alpha3=-1, alpha4=0.01
## + Fold06: alpha2=0.05, alpha3=-1, alpha4=0.05
## - Fold06: alpha2=0.05, alpha3=-1, alpha4=0.05
## + Fold06: alpha2=0.03, alpha3=-1, alpha4=0.03
## - Fold06: alpha2=0.03, alpha3=-1, alpha4=0.03
## + Fold06: alpha2=0.01, alpha3=-1, alpha4=0.01
## - Fold06: alpha2=0.01, alpha3=-1, alpha4=0.01
## + Fold07: alpha2=0.05, alpha3=-1, alpha4=0.05
## - Fold07: alpha2=0.05, alpha3=-1, alpha4=0.05
## + Fold07: alpha2=0.03, alpha3=-1, alpha4=0.03
## - Fold07: alpha2=0.03, alpha3=-1, alpha4=0.03
## + Fold07: alpha2=0.01, alpha3=-1, alpha4=0.01
## - Fold07: alpha2=0.01, alpha3=-1, alpha4=0.01
## + Fold08: alpha2=0.05, alpha3=-1, alpha4=0.05
## - Fold08: alpha2=0.05, alpha3=-1, alpha4=0.05
## + Fold08: alpha2=0.03, alpha3=-1, alpha4=0.03
## - Fold08: alpha2=0.03, alpha3=-1, alpha4=0.03
## + Fold08: alpha2=0.01, alpha3=-1, alpha4=0.01
## - Fold08: alpha2=0.01, alpha3=-1, alpha4=0.01
## + Fold09: alpha2=0.05, alpha3=-1, alpha4=0.05
## - Fold09: alpha2=0.05, alpha3=-1, alpha4=0.05
## + Fold09: alpha2=0.03, alpha3=-1, alpha4=0.03
## - Fold09: alpha2=0.03, alpha3=-1, alpha4=0.03
## + Fold09: alpha2=0.01, alpha3=-1, alpha4=0.01
## - Fold09: alpha2=0.01, alpha3=-1, alpha4=0.01
## + Fold10: alpha2=0.05, alpha3=-1, alpha4=0.05
## - Fold10: alpha2=0.05, alpha3=-1, alpha4=0.05
## + Fold10: alpha2=0.03, alpha3=-1, alpha4=0.03
## - Fold10: alpha2=0.03, alpha3=-1, alpha4=0.03
## + Fold10: alpha2=0.01, alpha3=-1, alpha4=0.01
## - Fold10: alpha2=0.01, alpha3=-1, alpha4=0.01
## Aggregating results
## Selecting tuning parameters
## Fitting alpha2 = 0.01, alpha3 = -1, alpha4 = 0.01 on full training setAnd…. we’re done. Turns out in this case the best solution was what chaid uses as defaults. The very last line of the output tells us that. But let’s use what we have used in the past for printing and plotting the results…
chaid.m1 #equivalent to print(chaid.m1)## CHi-squared Automated Interaction Detection
##
## 1030 samples
## 30 predictor
## 2 classes: 'No', 'Yes'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold)
## Summary of sample sizes: 927, 926, 927, 927, 928, 927, ...
## Resampling results across tuning parameters:
##
## alpha2 alpha4 Accuracy Kappa
## 0.01 0.01 0.8523834 0.2719169
## 0.03 0.03 0.8348795 0.2366848
## 0.05 0.05 0.8387817 0.2521903
##
## Tuning parameter 'alpha3' was held constant at a value of -1
## Kappa was used to select the optimal model using the largest value.
## The final values used for the model were alpha2 = 0.01, alpha3 = -1 and
## alpha4 = 0.01.plot(chaid.m1)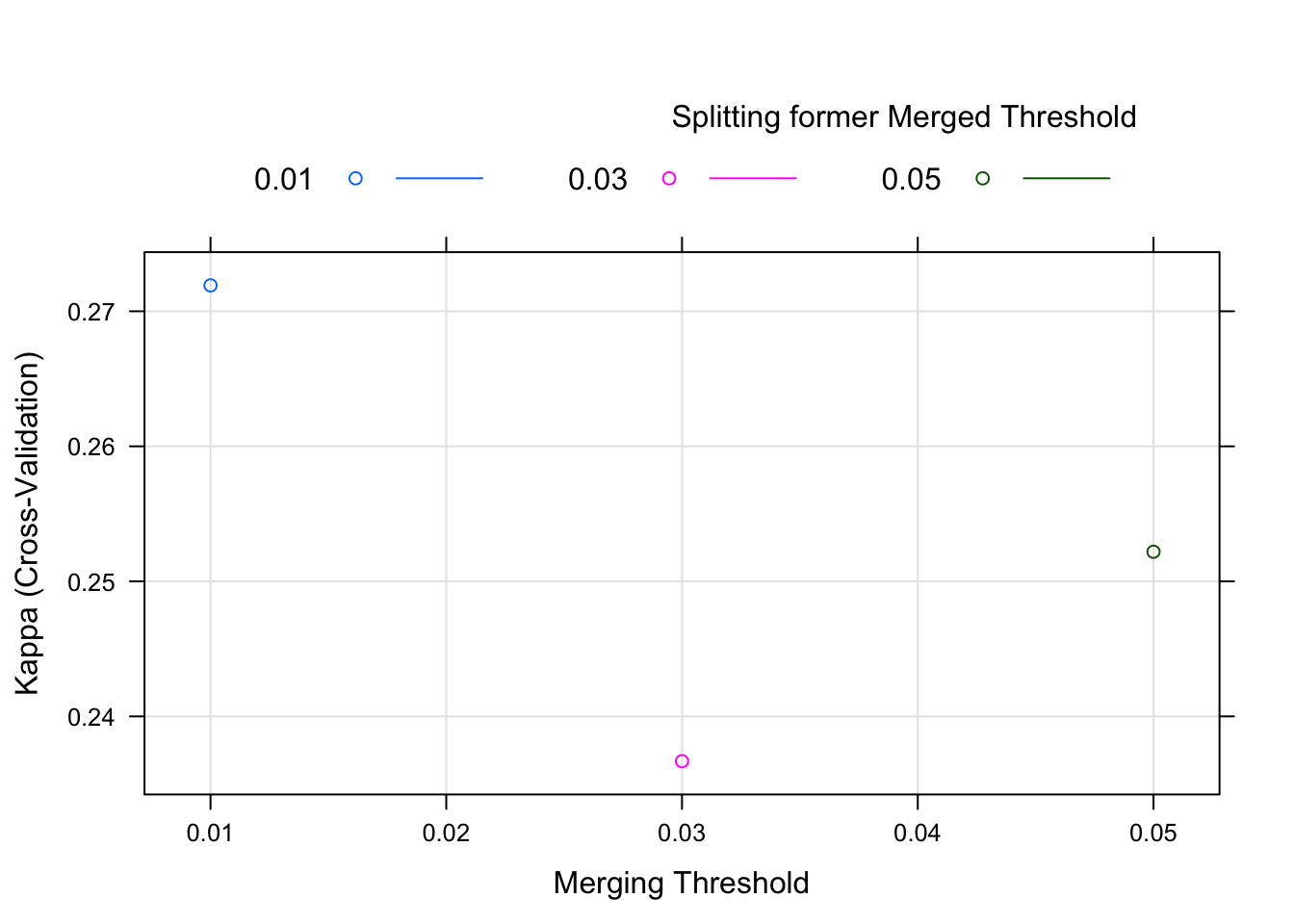
Wait. What? These are not the output we’re used to. caret has changed the
output from its’ work (an improvement actually) but we’ll have to change how we
get the information out. Before we do that however, let’s inspect what we have
so far. The output gives us a nice concise summary. 1030 cases with 30
predictors. It gives us an idea of how many of the 1030 cases were used in the
individual folds Summary of sample sizes: 928, 927, 927, 926, 928, 926, ....
The bit about alpha2, alpha4, and alpha3 is somewhat mysterious. We saw those names when we looked at the chaid_control documentation last post but why are they here? We’ll come back to that in a moment. But it is clear that it thought Kappa of 0.1692826 was best.
The plot isn’t what we’re used to seeing, but is easy to understand. Kappa is on the y axis, alpha2 on the x axis and it’s shaded/colored by alpha4 (remember we left alpha3 out of the mix). The plot is a bit of overkill for what we did but we’ll put it to better use later.
But what about the things we were used to seeing? Well if you remember that caret is reporting averages of all the folds it sort of makes sense that the best final model results are now in chaid.m1$finalModel so we need to use that when we print or plot. So in the next block of code let’s:
- Print the final model from
chaid(chaid.m1$finalModel) - Plot the final model from
chaid(plot(chaid.m1$finalModel)) - Produce the
confusionMatrixacross all folds (confusionMatrix(chaid.m1)) - Produce the
confusionMatrixusing the final model (confusionMatrix(predict(chaid.m1), y)) - Check on variable importance (
varImp(chaid.m1)) - The best tuning parameters are stored in
chaid.m1$bestTune - How long did it take? Look in
chaid.m1$times - In case you forgot what method you used look here
chaid.m1$method - We’ll look at model info in a bit
chaid.m1$modelInfo - The summarized results are here in a nice format if needed later
chaid.m1$results
Many of these you’ll never need but I wanted to at least give you a hint of how complete the chaid.m1 object is
chaid.m1$finalModel##
## Model formula:
## .outcome ~ Age + BusinessTravel + DailyRate + Department + DistanceFromHome +
## Education + EducationField + EnvironmentSatisfaction + Gender +
## HourlyRate + JobInvolvement + JobLevel + JobRole + JobSatisfaction +
## MaritalStatus + MonthlyIncome + MonthlyRate + NumCompaniesWorked +
## OverTime + PercentSalaryHike + PerformanceRating + RelationshipSatisfaction +
## StockOptionLevel + TotalWorkingYears + TrainingTimesLastYear +
## WorkLifeBalance + YearsAtCompany + YearsInCurrentRole + YearsSinceLastPromotion +
## YearsWithCurrManager
##
## Fitted party:
## [1] root
## | [2] OverTime in No
## | | [3] YearsWithCurrManager in [0,1]
## | | | [4] Age in [18,29], (29,34]: No (n = 80, err = 35.0%)
## | | | [5] Age in (34,38], (38,45], (45,60]: No (n = 74, err = 8.1%)
## | | [6] YearsWithCurrManager in (1,2], (2,4], (4,7], (7,17]
## | | | [7] JobSatisfaction in Low: No (n = 124, err = 14.5%)
## | | | [8] JobSatisfaction in Medium, High, Very_High: No (n = 458, err = 5.5%)
## | [9] OverTime in Yes
## | | [10] MaritalStatus in Divorced, Married
## | | | [11] JobLevel in 1: No (n = 67, err = 37.3%)
## | | | [12] JobLevel in 2, 3, 4, 5: No (n = 134, err = 9.7%)
## | | [13] MaritalStatus in Single
## | | | [14] Age in [18,29], (29,34]: Yes (n = 51, err = 25.5%)
## | | | [15] Age in (34,38], (38,45], (45,60]: No (n = 42, err = 31.0%)
##
## Number of inner nodes: 7
## Number of terminal nodes: 8plot(chaid.m1$finalModel)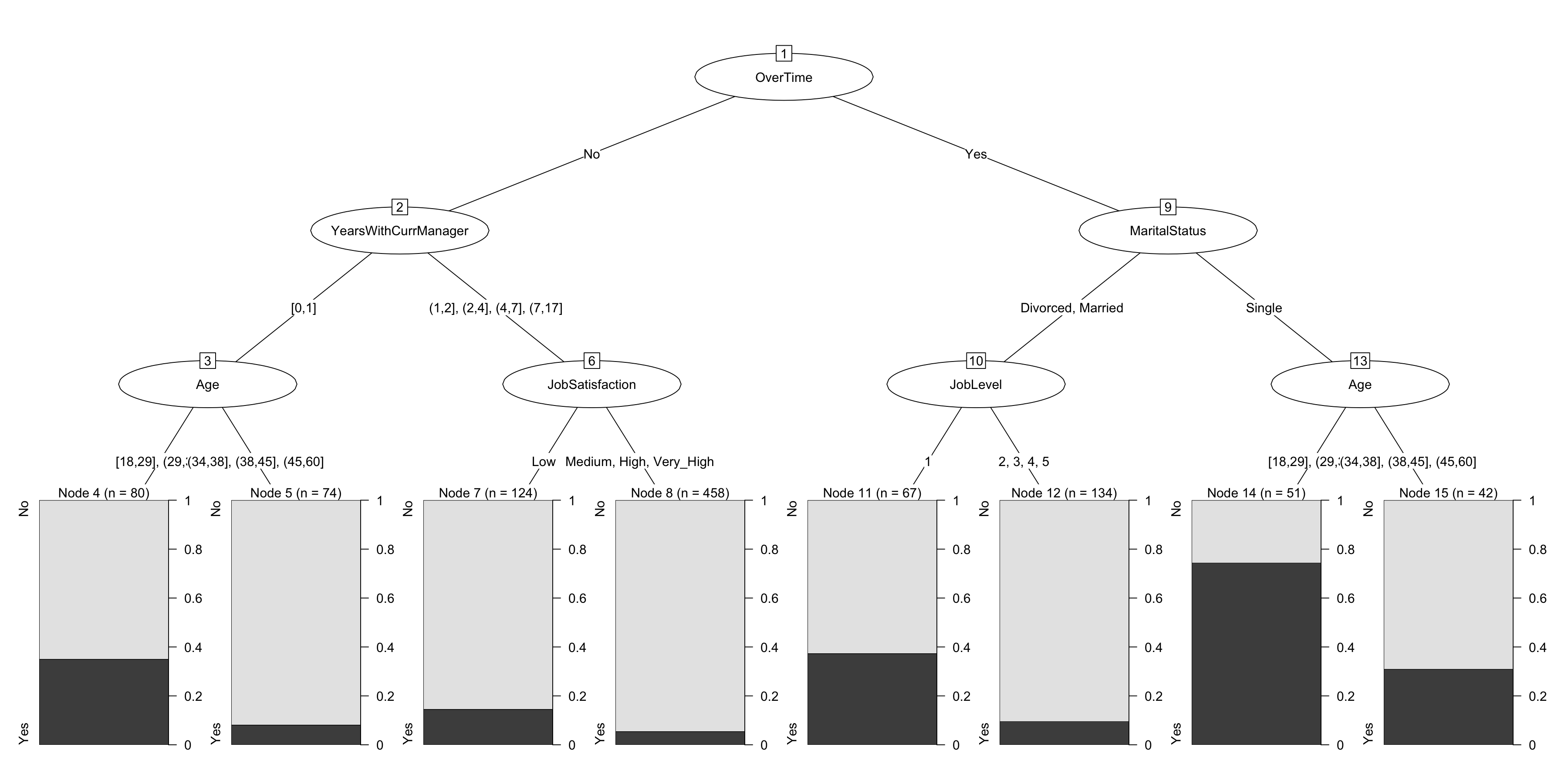
confusionMatrix(chaid.m1)## Cross-Validated (10 fold) Confusion Matrix
##
## (entries are percentual average cell counts across resamples)
##
## Reference
## Prediction No Yes
## No 81.4 12.2
## Yes 2.5 3.9
##
## Accuracy (average) : 0.8524confusionMatrix(predict(chaid.m1), y)## Confusion Matrix and Statistics
##
## Reference
## Prediction No Yes
## No 851 128
## Yes 13 38
##
## Accuracy : 0.8631
## 95% CI : (0.8406, 0.8835)
## No Information Rate : 0.8388
## P-Value [Acc > NIR] : 0.01741
##
## Kappa : 0.297
##
## Mcnemar's Test P-Value : < 2e-16
##
## Sensitivity : 0.9850
## Specificity : 0.2289
## Pos Pred Value : 0.8693
## Neg Pred Value : 0.7451
## Prevalence : 0.8388
## Detection Rate : 0.8262
## Detection Prevalence : 0.9505
## Balanced Accuracy : 0.6069
##
## 'Positive' Class : No
## varImp(chaid.m1)## ROC curve variable importance
##
## only 20 most important variables shown (out of 30)
##
## Importance
## TotalWorkingYears 100.00
## Age 99.31
## YearsInCurrentRole 90.64
## JobLevel 88.38
## YearsAtCompany 87.69
## OverTime 86.99
## MonthlyIncome 86.78
## YearsWithCurrManager 83.91
## MaritalStatus 82.98
## StockOptionLevel 66.82
## JobInvolvement 50.34
## EnvironmentSatisfaction 47.98
## JobRole 37.39
## JobSatisfaction 37.13
## DailyRate 33.53
## RelationshipSatisfaction 25.18
## DistanceFromHome 24.79
## Department 22.30
## Education 21.02
## TrainingTimesLastYear 20.38chaid.m1$bestTune## alpha2 alpha3 alpha4
## 1 0.01 -1 0.01chaid.m1$times## $everything
## user system elapsed
## 306.574 10.711 317.380
##
## $final
## user system elapsed
## 6.219 0.207 6.429
##
## $prediction
## [1] NA NA NAchaid.m1$method## [1] "chaid"chaid.m1$modelInfo## $label
## [1] "CHi-squared Automated Interaction Detection"
##
## $library
## [1] "CHAID"
##
## $loop
## NULL
##
## $type
## [1] "Classification"
##
## $parameters
## parameter class
## 1 alpha2 numeric
## 2 alpha3 numeric
## 3 alpha4 numeric
## label
## 1 Merging Threshold
## 2 Splitting former Merged Threshold
## 3 \n Splitting former Merged Threshold
##
## $grid
## function(x, y, len = NULL, search = "grid") {
## if(search == "grid") {
## out <- data.frame(alpha2 = seq(from = .05, to = 0.01, length = len),
## alpha3 = -1,
## alpha4 = seq(from = .05, to = 0.01, length = len))
## } else {
## out <- data.frame(alpha2 = runif(len, min = 0.000001, max = .1),
## alpha3 = runif(len, min =-.1, max = .1),
## alpha4 = runif(len, min = 0.000001, max = .1))
## }
## out
## }
##
## $fit
## function(x, y, wts, param, lev, last, classProbs, ...) {
## dat <- if(is.data.frame(x)) x else as.data.frame(x, stringsAsFactors = TRUE)
## dat$.outcome <- y
## theDots <- list(...)
## if(any(names(theDots) == "control")) {
## theDots$control$alpha2 <- param$alpha2
## theDots$control$alpha3 <- param$alpha3
## theDots$control$alpha4 <- param$alpha4
## ctl <- theDots$control
## theDots$control <- NULL
## } else ctl <- CHAID::chaid_control(alpha2 = param$alpha2,
## alpha3 = param$alpha3,
## alpha4 = param$alpha4)
## ## pass in any model weights
## if(!is.null(wts)) theDots$weights <- wts
## modelArgs <- c(
## list(
## formula = as.formula(".outcome ~ ."),
## data = dat,
## control = ctl),
## theDots)
## out <- do.call(CHAID::chaid, modelArgs)
## out
## }
## <bytecode: 0x7fe39aa4adb8>
##
## $predict
## function(modelFit, newdata, submodels = NULL) {
## if(!is.data.frame(newdata)) newdata <- as.data.frame(newdata, stringsAsFactors = TRUE)
## predict(modelFit, newdata)
## }
## <bytecode: 0x7fe39aa37678>
##
## $prob
## function(modelFit, newdata, submodels = NULL) {
## if(!is.data.frame(newdata)) newdata <- as.data.frame(newdata, stringsAsFactors = TRUE)
## predict(modelFit, newdata, type = "prob")
## }
##
## $levels
## function(x) x$obsLevels
##
## $predictors
## function(x, surrogate = TRUE, ...) {
## predictors(terms(x))
## }
##
## $tags
## [1] "Tree-Based Model" "Implicit Feature Selection"
## [3] "Two Class Only" "Accepts Case Weights"
##
## $sort
## function(x) x[order(-x$alpha2, -x$alpha4, -x$alpha3),]chaid.m1$results## alpha2 alpha3 alpha4 Accuracy Kappa AccuracySD KappaSD
## 1 0.01 -1 0.01 0.8523834 0.2719169 0.01558170 0.09809214
## 2 0.03 -1 0.03 0.8348795 0.2366848 0.01525867 0.07903586
## 3 0.05 -1 0.05 0.8387817 0.2521903 0.01717964 0.10664906Let’s tune it up a little
Having mastered the basics of using caret and chaid let’s explore a little deeper. By default caret allows us to adjust three parameters in our chaid model; alpha2, alpha3, and alpha4. As a matter of fact it will allow us to build a grid of those parameters and test all the permutations we like, using the same cross-validation process. I’m a bit worried that we’re not being conservative enough. I’d like to train our model using p values for alpha that are not .05, .03, and .01 but instead the de facto levels in my discipline; .05, .01, and .001. The function in caret is tuneGrid. We’ll use the base R function expand.grid to build a dataframe with all the combinations and then feed it to caret in our next training.
Therefore search_grid will hold the values and we’ll add the line tuneGrid = search_grid to our call to train. We’ll call the results chaid.m2 and see how we did (I’m turning off verbose iteration output since you’ve seen it on screen once already)…
# set up tuning grid default
search_grid <- expand.grid(
alpha2 = c(.05, .01, .001),
alpha4 = c(.05, .01, .001),
alpha3 = -1
)
# no verbose
train_control <- trainControl(method = "cv",
number = 10,
savePredictions = "final")
# train model
chaid.m2 <- train(
x = x,
y = y,
method = "chaid",
metric = "Kappa",
trControl = train_control,
tuneGrid = search_grid
)
chaid.m2## CHi-squared Automated Interaction Detection
##
## 1030 samples
## 30 predictor
## 2 classes: 'No', 'Yes'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold)
## Summary of sample sizes: 927, 928, 927, 928, 926, 927, ...
## Resampling results across tuning parameters:
##
## alpha2 alpha4 Accuracy Kappa
## 0.001 0.001 0.8456250 0.2809808
## 0.001 0.010 0.8485942 0.2530414
## 0.001 0.050 0.8379521 0.2735816
## 0.010 0.001 0.8408173 0.2512891
## 0.010 0.010 0.8476327 0.2516209
## 0.010 0.050 0.8389135 0.2929631
## 0.050 0.001 0.8408173 0.2512891
## 0.050 0.010 0.8447387 0.2511713
## 0.050 0.050 0.8360479 0.2816001
##
## Tuning parameter 'alpha3' was held constant at a value of -1
## Kappa was used to select the optimal model using the largest value.
## The final values used for the model were alpha2 = 0.01, alpha3 = -1 and
## alpha4 = 0.05.plot(chaid.m2)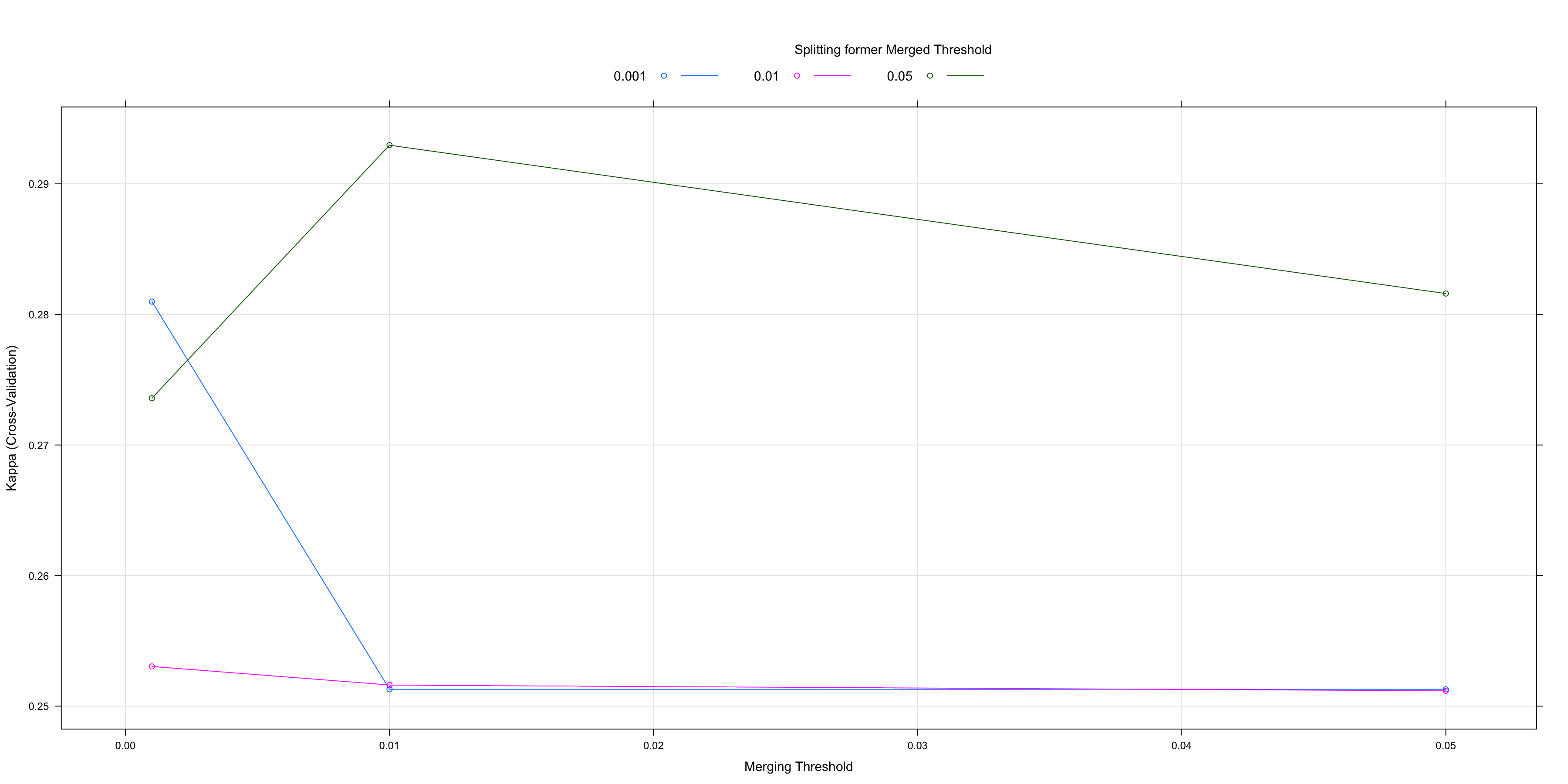
chaid.m2$finalModel##
## Model formula:
## .outcome ~ Age + BusinessTravel + DailyRate + Department + DistanceFromHome +
## Education + EducationField + EnvironmentSatisfaction + Gender +
## HourlyRate + JobInvolvement + JobLevel + JobRole + JobSatisfaction +
## MaritalStatus + MonthlyIncome + MonthlyRate + NumCompaniesWorked +
## OverTime + PercentSalaryHike + PerformanceRating + RelationshipSatisfaction +
## StockOptionLevel + TotalWorkingYears + TrainingTimesLastYear +
## WorkLifeBalance + YearsAtCompany + YearsInCurrentRole + YearsSinceLastPromotion +
## YearsWithCurrManager
##
## Fitted party:
## [1] root
## | [2] OverTime in No
## | | [3] YearsWithCurrManager in [0,1]
## | | | [4] Age in [18,29], (29,34]
## | | | | [5] EnvironmentSatisfaction in Low: Yes (n = 19, err = 36.8%)
## | | | | [6] EnvironmentSatisfaction in Medium, High, Very_High: No (n = 61, err = 26.2%)
## | | | [7] Age in (34,38], (38,45], (45,60]: No (n = 74, err = 8.1%)
## | | [8] YearsWithCurrManager in (1,2], (2,4], (4,7], (7,17]
## | | | [9] JobSatisfaction in Low: No (n = 124, err = 14.5%)
## | | | [10] JobSatisfaction in Medium, High, Very_High
## | | | | [11] BusinessTravel in Non-Travel, Travel_Rarely
## | | | | | [12] JobLevel in 1, 2, 4, 5
## | | | | | | [13] JobInvolvement in Low: No (n = 15, err = 13.3%)
## | | | | | | [14] JobInvolvement in Medium, High, Very_High: No (n = 297, err = 1.7%)
## | | | | | [15] JobLevel in 3
## | | | | | | [16] Department in Human_Resources, Research_Development: No (n = 46, err = 4.3%)
## | | | | | | [17] Department in Sales: No (n = 16, err = 37.5%)
## | | | | [18] BusinessTravel in Travel_Frequently: No (n = 84, err = 11.9%)
## | [19] OverTime in Yes
## | | [20] MaritalStatus in Divorced, Married
## | | | [21] JobLevel in 1
## | | | | [22] Age in [18,29]: Yes (n = 24, err = 37.5%)
## | | | | [23] Age in (29,34], (34,38], (38,45], (45,60]: No (n = 43, err = 23.3%)
## | | | [24] JobLevel in 2, 3, 4, 5
## | | | | [25] EnvironmentSatisfaction in Low, Medium
## | | | | | [26] YearsSinceLastPromotion in Less than 1, 1, More than 2: No (n = 45, err = 13.3%)
## | | | | | [27] YearsSinceLastPromotion in 2: Yes (n = 3, err = 0.0%)
## | | | | [28] EnvironmentSatisfaction in High, Very_High: No (n = 86, err = 4.7%)
## | | [29] MaritalStatus in Single
## | | | [30] Age in [18,29], (29,34]
## | | | | [31] DistanceFromHome in [1,2], (2,5], (5,9]: Yes (n = 33, err = 39.4%)
## | | | | [32] DistanceFromHome in (9,17], (17,29]: Yes (n = 18, err = 0.0%)
## | | | [33] Age in (34,38], (38,45], (45,60]
## | | | | [34] JobSatisfaction in Low, Medium, High
## | | | | | [35] Department in Human_Resources, Research_Development: No (n = 16, err = 25.0%)
## | | | | | [36] Department in Sales: Yes (n = 9, err = 11.1%)
## | | | | [37] JobSatisfaction in Very_High: No (n = 17, err = 5.9%)
##
## Number of inner nodes: 18
## Number of terminal nodes: 19plot(chaid.m2$finalModel)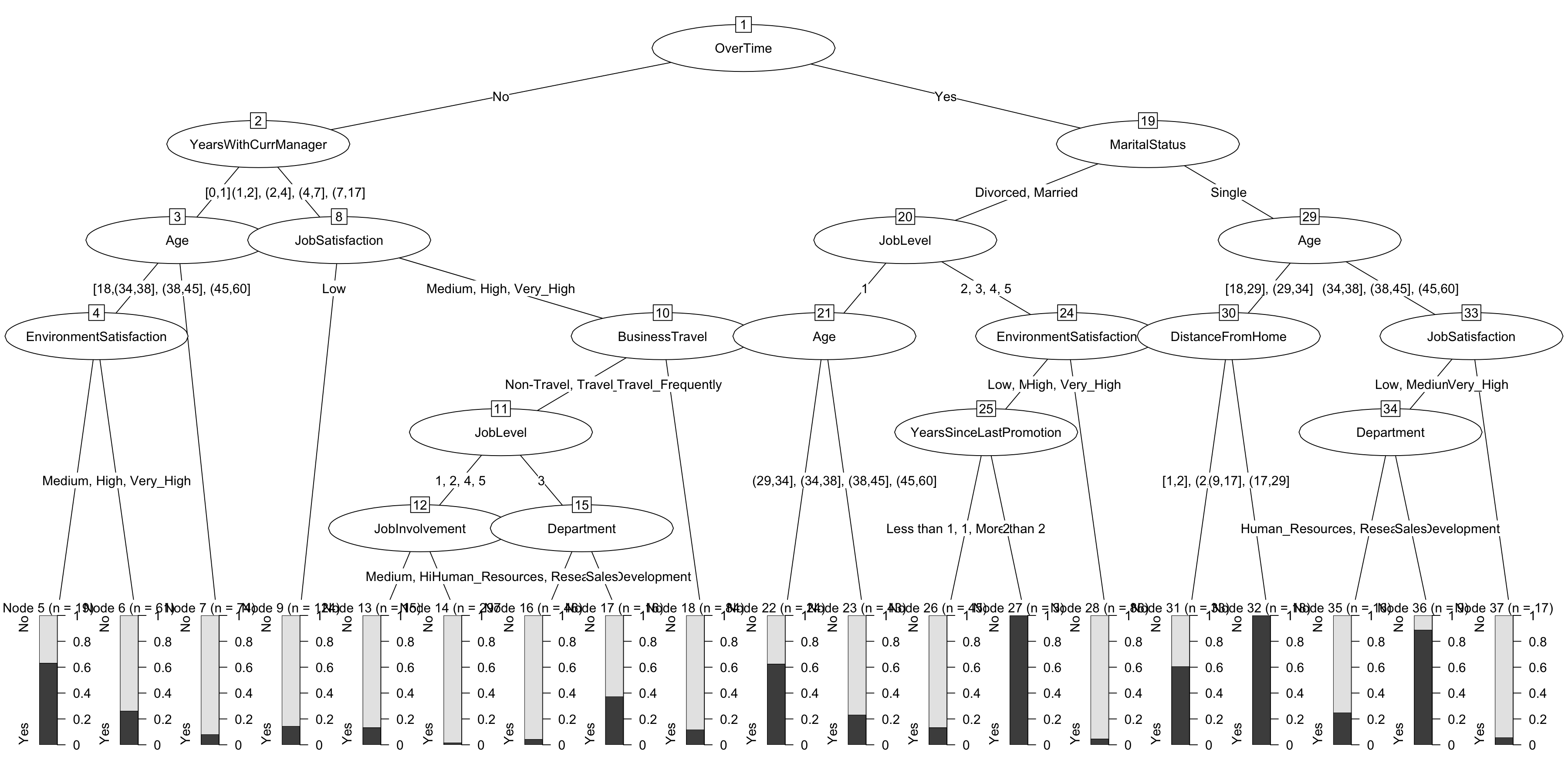
confusionMatrix(chaid.m2)## Cross-Validated (10 fold) Confusion Matrix
##
## (entries are percentual average cell counts across resamples)
##
## Reference
## Prediction No Yes
## No 78.9 11.2
## Yes 5.0 5.0
##
## Accuracy (average) : 0.8388confusionMatrix(predict(chaid.m2), y)## Confusion Matrix and Statistics
##
## Reference
## Prediction No Yes
## No 834 90
## Yes 30 76
##
## Accuracy : 0.8835
## 95% CI : (0.8623, 0.9025)
## No Information Rate : 0.8388
## P-Value [Acc > NIR] : 3.051e-05
##
## Kappa : 0.4954
##
## Mcnemar's Test P-Value : 7.207e-08
##
## Sensitivity : 0.9653
## Specificity : 0.4578
## Pos Pred Value : 0.9026
## Neg Pred Value : 0.7170
## Prevalence : 0.8388
## Detection Rate : 0.8097
## Detection Prevalence : 0.8971
## Balanced Accuracy : 0.7116
##
## 'Positive' Class : No
## chaid.m2$times## $everything
## user system elapsed
## 780.758 26.594 807.843
##
## $final
## user system elapsed
## 12.266 0.428 12.708
##
## $prediction
## [1] NA NA NAchaid.m2$results## alpha2 alpha4 alpha3 Accuracy Kappa AccuracySD KappaSD
## 1 0.001 0.001 -1 0.8456250 0.2809808 0.01167313 0.1170377
## 2 0.001 0.010 -1 0.8485942 0.2530414 0.02505017 0.1471452
## 3 0.001 0.050 -1 0.8379521 0.2735816 0.02641648 0.1500928
## 4 0.010 0.001 -1 0.8408173 0.2512891 0.02155179 0.1494622
## 5 0.010 0.010 -1 0.8476327 0.2516209 0.02766307 0.1500421
## 6 0.010 0.050 -1 0.8389135 0.2929631 0.02571900 0.1128782
## 7 0.050 0.001 -1 0.8408173 0.2512891 0.02155179 0.1494622
## 8 0.050 0.010 -1 0.8447387 0.2511713 0.03359797 0.1590970
## 9 0.050 0.050 -1 0.8360479 0.2816001 0.03649882 0.1563142Very nice! Some key points here. Even though our model got more conservative and has far fewer nodes, our accuracy has improved as measured both by traditional accuracy and Kappa. That applies at both the average fold level but more importantly at the best model prediction stage. Later on we’ll start using our models to predict against the data we held out in test.
The plot is also more useful now. No matter what we do with alpha2 it pays to keep alpha4 conservative at .001 (blue line always on top) but keeping alpha2 modest seems to be best.
This goes to the heart of our conversation about over-fitting. While it may seem like 1,400+ cases is a lot of data we are at great risk of over-fitting if we try and build too complex a model, so sometimes a conservative track is warranted.
A Custom caret model
Earlier I printed the results of chaid.m1$modelInfo and then pretty much skipped over discussing them. Under the covers one of the strengths of caret is that it keeps some default information about how to tune various types of algorithms. They are visible at https://github.com/topepo/caret/tree/master/models/files.
My experience is that they are quite comprehensive and allow you to get your modelling done. But sometimes you want to do something your own way or different and caret has provisions for that. If you look at the default model setup for CHAID here on GITHUB you can see that it only allows you to tune on alpha2, alpha3, and alpha4 by default. That is not a comprehensive list of all the parameters we can work with in chaid_control see ?chaid_control for a listing and brief description of what they all are.
What if, for example, we wanted to tune based upon minsplit, minbucket, minprob, maxheight instead? How would we go about using all the built in functionality in caret but have it our way? There’s a section in the caret documentation called “Using Your Own Model In Train” that does a great job of walking you through the steps. At first it looked a little too complicated for my tastes, but I found that with a bit of trial and error I was able to hack up the existing list that I found on GITHUB and convert it into a list in my local environment that worked perfectly for my needs.
I won’t bore you with all the details and the documentation is quite good so it wound up being mainly a search and replace operation and adding one parameter. I decided to call my version cgpCHAID and here’s what the version looks like.
# hack up my own
cgpCHAID <- list(label = "CGP CHAID",
library = "CHAID",
loop = NULL,
type = c("Classification"),
parameters = data.frame(parameter = c('minsplit', 'minbucket', 'minprob', 'maxheight'),
class = rep('numeric', 4),
label = c('Numb obs in response where no further split',
"Minimum numb obs in terminal nodes",
"Minimum freq of obs in terminal nodes.",
"Maximum height for the tree")
),
grid = function(x, y, len = NULL, search = "grid") {
if(search == "grid") {
out <- data.frame(minsplit = c(20,30),
minbucket = 7,
minprob = c(0.05,0.01),
maxheight = -1)
} else {
out <- data.frame(minsplit = c(20,30),
minbucket = 7,
minprob = c(0.05,0.01),
maxheight = -1)
}
out
},
fit = function(x, y, wts, param, lev, last, classProbs, ...) {
dat <- if(is.data.frame(x)) x else as.data.frame(x)
dat$.outcome <- y
theDots <- list(...)
if(any(names(theDots) == "control")) {
theDots$control$minsplit <- param$minsplit
theDots$control$minbucket <- param$minbucket
theDots$control$minprob <- param$minprob
theDots$control$maxheight <- param$maxheight
ctl <- theDots$control
theDots$control <- NULL
} else ctl <- chaid_control(minsplit = param$minsplit,
minbucket = param$minbucket,
minprob = param$minprob,
maxheight = param$maxheight)
## pass in any model weights
if(!is.null(wts)) theDots$weights <- wts
modelArgs <- c(
list(
formula = as.formula(".outcome ~ ."),
data = dat,
control = ctl),
theDots)
out <- do.call(CHAID::chaid, modelArgs)
out
},
predict = function(modelFit, newdata, submodels = NULL) {
if(!is.data.frame(newdata)) newdata <- as.data.frame(newdata)
predict(modelFit, newdata)
},
prob = function(modelFit, newdata, submodels = NULL) {
if(!is.data.frame(newdata)) newdata <- as.data.frame(newdata)
predict(modelFit, newdata, type = "prob")
},
levels = function(x) x$obsLevels,
predictors = function(x, surrogate = TRUE, ...) {
predictors(terms(x))
},
tags = c('Tree-Based Model', "Implicit Feature Selection", "Two Class Only", "Accepts Case Weights"),
sort = function(x) x[order(-x$minsplit, -x$minbucket, -x$minprob, -x$maxheight),])
cgpCHAID## $label
## [1] "CGP CHAID"
##
## $library
## [1] "CHAID"
##
## $loop
## NULL
##
## $type
## [1] "Classification"
##
## $parameters
## parameter class label
## 1 minsplit numeric Numb obs in response where no further split
## 2 minbucket numeric Minimum numb obs in terminal nodes
## 3 minprob numeric Minimum freq of obs in terminal nodes.
## 4 maxheight numeric Maximum height for the tree
##
## $grid
## function(x, y, len = NULL, search = "grid") {
## if(search == "grid") {
## out <- data.frame(minsplit = c(20,30),
## minbucket = 7,
## minprob = c(0.05,0.01),
## maxheight = -1)
## } else {
## out <- data.frame(minsplit = c(20,30),
## minbucket = 7,
## minprob = c(0.05,0.01),
## maxheight = -1)
## }
## out
## }
##
## $fit
## function(x, y, wts, param, lev, last, classProbs, ...) {
## dat <- if(is.data.frame(x)) x else as.data.frame(x)
## dat$.outcome <- y
## theDots <- list(...)
## if(any(names(theDots) == "control")) {
## theDots$control$minsplit <- param$minsplit
## theDots$control$minbucket <- param$minbucket
## theDots$control$minprob <- param$minprob
## theDots$control$maxheight <- param$maxheight
## ctl <- theDots$control
## theDots$control <- NULL
## } else ctl <- chaid_control(minsplit = param$minsplit,
## minbucket = param$minbucket,
## minprob = param$minprob,
## maxheight = param$maxheight)
## ## pass in any model weights
## if(!is.null(wts)) theDots$weights <- wts
## modelArgs <- c(
## list(
## formula = as.formula(".outcome ~ ."),
## data = dat,
## control = ctl),
## theDots)
## out <- do.call(CHAID::chaid, modelArgs)
## out
## }
##
## $predict
## function(modelFit, newdata, submodels = NULL) {
## if(!is.data.frame(newdata)) newdata <- as.data.frame(newdata)
## predict(modelFit, newdata)
## }
##
## $prob
## function(modelFit, newdata, submodels = NULL) {
## if(!is.data.frame(newdata)) newdata <- as.data.frame(newdata)
## predict(modelFit, newdata, type = "prob")
## }
##
## $levels
## function(x) x$obsLevels
##
## $predictors
## function(x, surrogate = TRUE, ...) {
## predictors(terms(x))
## }
##
## $tags
## [1] "Tree-Based Model" "Implicit Feature Selection"
## [3] "Two Class Only" "Accepts Case Weights"
##
## $sort
## function(x) x[order(-x$minsplit, -x$minbucket, -x$minprob, -x$maxheight),]The final print statement shows what it looks like and confirms it is there ready for us to use in the local environment. The original chaid version in caret remains untouched and available in caret for when we want it. To make use of our custom model we simply rebuild our search grid using our new parameters.
# set up tuning grid cgpCHAID
search_grid <- expand.grid(
minsplit = c(30,40),
minprob = .1,
minbucket = 25,
maxheight = 4
)
search_grid## minsplit minprob minbucket maxheight
## 1 30 0.1 25 4
## 2 40 0.1 25 4Then to use it to train our third model chaid.m3 we insert it into the method directive (not quoted because it’s in the local environment).
# train model
chaid.m3 <- train(
x = x,
y = y,
method = cgpCHAID,
trControl = train_control,
metric = "Kappa",
tuneGrid = search_grid
)The process runs for a few minutes and then produces output very similar to what we received for chaid.m2. We get summarized information across our 10 folds and the all important The final values used for the model were minsplit = 40, minbucket = 25, minprob = 0.1 and maxheight = 4. I won’t review all the details since I’ve already covered it I’ve simply printed it out to confirm it all works.
chaid.m3## CGP CHAID
##
## 1030 samples
## 30 predictor
## 2 classes: 'No', 'Yes'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold)
## Summary of sample sizes: 928, 928, 927, 927, 927, 927, ...
## Resampling results across tuning parameters:
##
## minsplit Accuracy Kappa
## 30 0.8397899 0.2112184
## 40 0.8408084 0.2312364
##
## Tuning parameter 'minbucket' was held constant at a value of 25
##
## Tuning parameter 'minprob' was held constant at a value of 0.1
##
## Tuning parameter 'maxheight' was held constant at a value of 4
## Kappa was used to select the optimal model using the largest value.
## The final values used for the model were minsplit = 40, minbucket = 25,
## minprob = 0.1 and maxheight = 4.chaid.m3$finalModel##
## Model formula:
## .outcome ~ Age + BusinessTravel + DailyRate + Department + DistanceFromHome +
## Education + EducationField + EnvironmentSatisfaction + Gender +
## HourlyRate + JobInvolvement + JobLevel + JobRole + JobSatisfaction +
## MaritalStatus + MonthlyIncome + MonthlyRate + NumCompaniesWorked +
## OverTime + PercentSalaryHike + PerformanceRating + RelationshipSatisfaction +
## StockOptionLevel + TotalWorkingYears + TrainingTimesLastYear +
## WorkLifeBalance + YearsAtCompany + YearsInCurrentRole + YearsSinceLastPromotion +
## YearsWithCurrManager
##
## Fitted party:
## [1] root
## | [2] OverTime in No
## | | [3] YearsWithCurrManager in [0,1]
## | | | [4] Age in [18,29], (29,34]
## | | | | [5] EnvironmentSatisfaction in Low: Yes (n = 19, err = 36.8%)
## | | | | [6] EnvironmentSatisfaction in Medium, High, Very_High: No (n = 61, err = 26.2%)
## | | | [7] Age in (34,38], (38,45], (45,60]: No (n = 74, err = 8.1%)
## | | [8] YearsWithCurrManager in (1,2], (2,4], (4,7], (7,17]
## | | | [9] JobSatisfaction in Low: No (n = 124, err = 14.5%)
## | | | [10] JobSatisfaction in Medium, High, Very_High
## | | | | [11] BusinessTravel in Non-Travel, Travel_Rarely: No (n = 374, err = 4.0%)
## | | | | [12] BusinessTravel in Travel_Frequently: No (n = 84, err = 11.9%)
## | [13] OverTime in Yes
## | | [14] MaritalStatus in Divorced, Married
## | | | [15] JobLevel in 1
## | | | | [16] Age in [18,29]: Yes (n = 24, err = 37.5%)
## | | | | [17] Age in (29,34], (34,38], (38,45], (45,60]: No (n = 43, err = 23.3%)
## | | | [18] JobLevel in 2, 3, 4, 5
## | | | | [19] YearsInCurrentRole in [0,1], (2,4], (4,7]: No (n = 70, err = 8.6%)
## | | | | [20] YearsInCurrentRole in (1,2]: No (n = 23, err = 30.4%)
## | | | | [21] YearsInCurrentRole in (7,18]: No (n = 41, err = 0.0%)
## | | [22] MaritalStatus in Single
## | | | [23] Age in [18,29], (29,34]
## | | | | [24] DistanceFromHome in [1,2], (2,5], (5,9]: Yes (n = 33, err = 39.4%)
## | | | | [25] DistanceFromHome in (9,17], (17,29]: Yes (n = 18, err = 0.0%)
## | | | [26] Age in (34,38], (38,45], (45,60]
## | | | | [27] JobSatisfaction in Low, Medium, High: No (n = 25, err = 48.0%)
## | | | | [28] JobSatisfaction in Very_High: No (n = 17, err = 5.9%)
##
## Number of inner nodes: 13
## Number of terminal nodes: 15confusionMatrix(chaid.m3)## Cross-Validated (10 fold) Confusion Matrix
##
## (entries are percentual average cell counts across resamples)
##
## Reference
## Prediction No Yes
## No 80.5 12.5
## Yes 3.4 3.6
##
## Accuracy (average) : 0.8408confusionMatrix(predict(chaid.m3), y)## Confusion Matrix and Statistics
##
## Reference
## Prediction No Yes
## No 835 101
## Yes 29 65
##
## Accuracy : 0.8738
## 95% CI : (0.8519, 0.8935)
## No Information Rate : 0.8388
## P-Value [Acc > NIR] : 0.0009858
##
## Kappa : 0.434
##
## Mcnemar's Test P-Value : 4.751e-10
##
## Sensitivity : 0.9664
## Specificity : 0.3916
## Pos Pred Value : 0.8921
## Neg Pred Value : 0.6915
## Prevalence : 0.8388
## Detection Rate : 0.8107
## Detection Prevalence : 0.9087
## Balanced Accuracy : 0.6790
##
## 'Positive' Class : No
## plot(chaid.m3)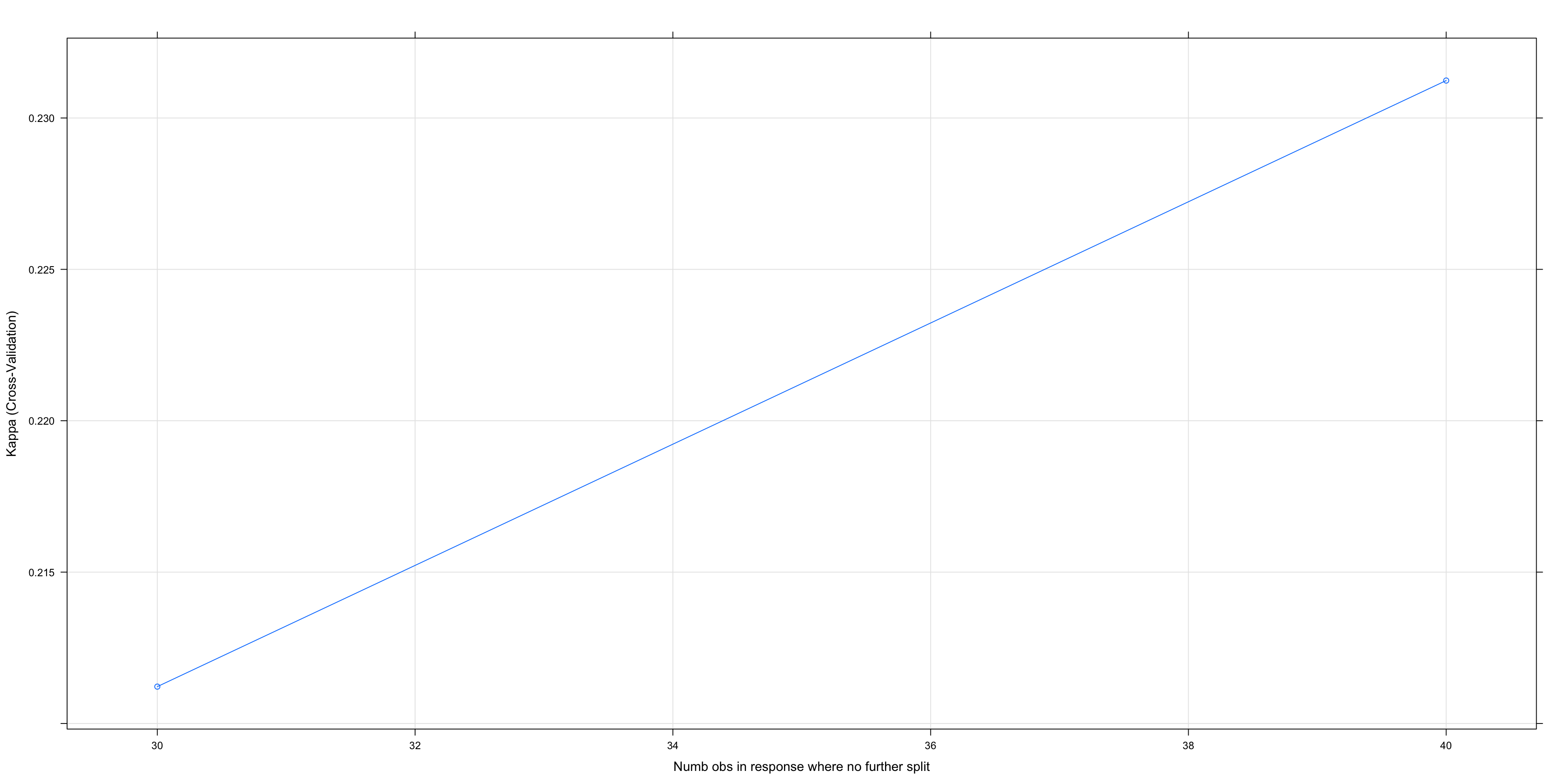
plot(chaid.m3$finalModel)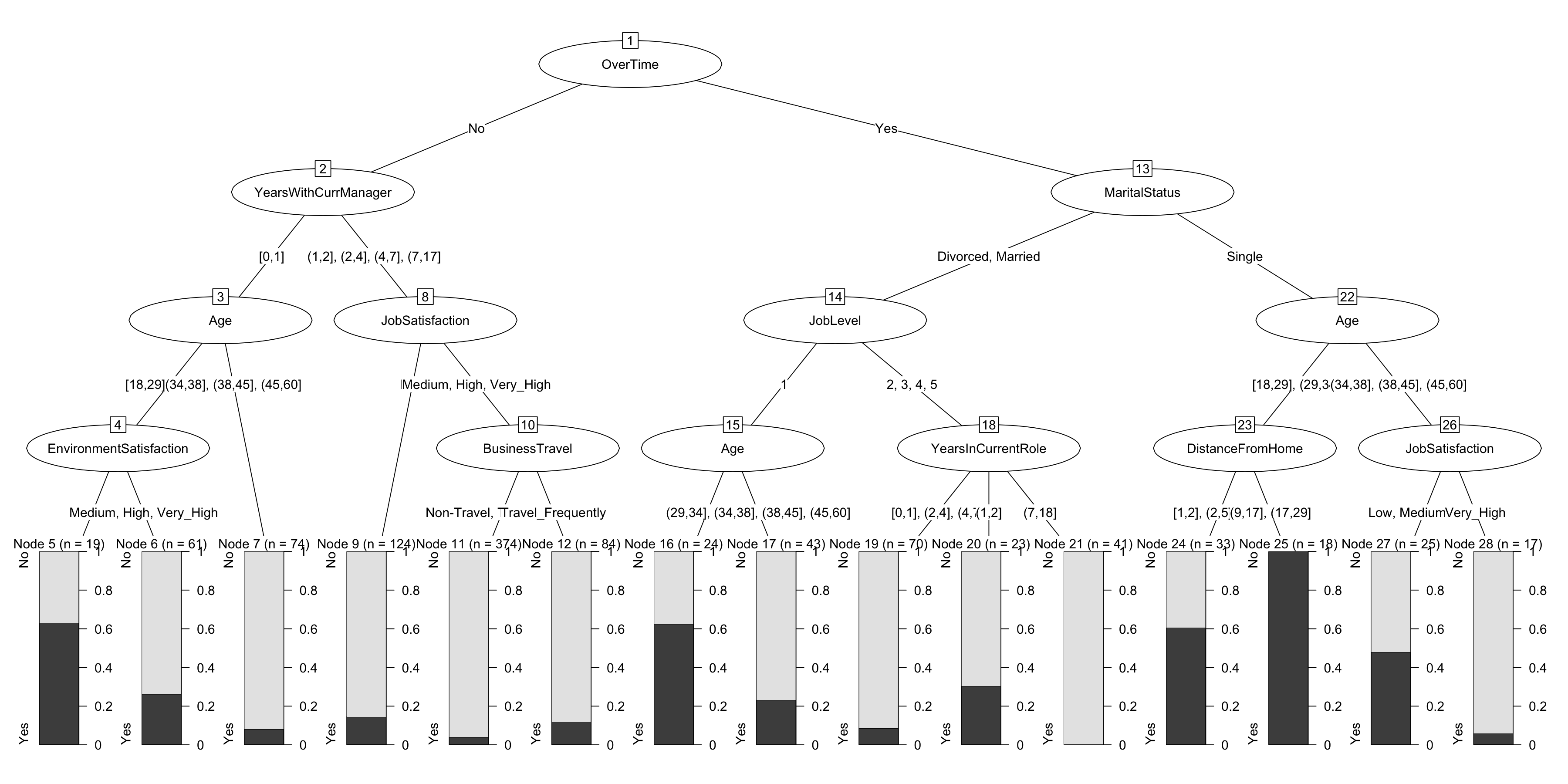
A quick reminder that you can get relative variable importance with varImp. And of course the all important look at how well we predicted against our held out test data set.
varImp(chaid.m3)## ROC curve variable importance
##
## only 20 most important variables shown (out of 30)
##
## Importance
## TotalWorkingYears 100.00
## Age 99.31
## YearsInCurrentRole 90.64
## JobLevel 88.38
## YearsAtCompany 87.69
## OverTime 86.99
## MonthlyIncome 86.78
## YearsWithCurrManager 83.91
## MaritalStatus 82.98
## StockOptionLevel 66.82
## JobInvolvement 50.34
## EnvironmentSatisfaction 47.98
## JobRole 37.39
## JobSatisfaction 37.13
## DailyRate 33.53
## RelationshipSatisfaction 25.18
## DistanceFromHome 24.79
## Department 22.30
## Education 21.02
## TrainingTimesLastYear 20.38confusionMatrix(predict(chaid.m3, newdata = test), test$Attrition)## Confusion Matrix and Statistics
##
## Reference
## Prediction No Yes
## No 348 56
## Yes 21 15
##
## Accuracy : 0.825
## 95% CI : (0.7862, 0.8594)
## No Information Rate : 0.8386
## P-Value [Acc > NIR] : 0.8014235
##
## Kappa : 0.1927
##
## Mcnemar's Test P-Value : 0.0001068
##
## Sensitivity : 0.9431
## Specificity : 0.2113
## Pos Pred Value : 0.8614
## Neg Pred Value : 0.4167
## Prevalence : 0.8386
## Detection Rate : 0.7909
## Detection Prevalence : 0.9182
## Balanced Accuracy : 0.5772
##
## 'Positive' Class : No
## One last exercise might also be fruitful. Suppose the only thing you wanted to tell chaid was how deeply it was allowed to go in the tree. Let’s run a simple example where we use all the defaults but force either a two level or three level solution.
# set up tuning grid cgpCHAID
search_grid <- expand.grid(
minsplit = c(30),
minprob = .01,
minbucket = 7,
maxheight = 3:4
)
# train model
chaid.m4 <- train(
x = x,
y = y,
method = cgpCHAID,
metric = "Kappa",
trControl = train_control,
tuneGrid = search_grid
)Those simple steps produce chaid.m4 which we can then investigate in the usual way.
chaid.m4## CGP CHAID
##
## 1030 samples
## 30 predictor
## 2 classes: 'No', 'Yes'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold)
## Summary of sample sizes: 927, 928, 927, 926, 927, 926, ...
## Resampling results across tuning parameters:
##
## maxheight Accuracy Kappa
## 3 0.8426747 0.2267845
## 4 0.8262070 0.2438140
##
## Tuning parameter 'minsplit' was held constant at a value of 30
## Tuning
## parameter 'minbucket' was held constant at a value of 7
## Tuning
## parameter 'minprob' was held constant at a value of 0.01
## Kappa was used to select the optimal model using the largest value.
## The final values used for the model were minsplit = 30, minbucket = 7,
## minprob = 0.01 and maxheight = 4.chaid.m4$finalModel##
## Model formula:
## .outcome ~ Age + BusinessTravel + DailyRate + Department + DistanceFromHome +
## Education + EducationField + EnvironmentSatisfaction + Gender +
## HourlyRate + JobInvolvement + JobLevel + JobRole + JobSatisfaction +
## MaritalStatus + MonthlyIncome + MonthlyRate + NumCompaniesWorked +
## OverTime + PercentSalaryHike + PerformanceRating + RelationshipSatisfaction +
## StockOptionLevel + TotalWorkingYears + TrainingTimesLastYear +
## WorkLifeBalance + YearsAtCompany + YearsInCurrentRole + YearsSinceLastPromotion +
## YearsWithCurrManager
##
## Fitted party:
## [1] root
## | [2] OverTime in No
## | | [3] YearsWithCurrManager in [0,1]
## | | | [4] Age in [18,29], (29,34]
## | | | | [5] EnvironmentSatisfaction in Low: Yes (n = 19, err = 36.8%)
## | | | | [6] EnvironmentSatisfaction in Medium, High, Very_High: No (n = 61, err = 26.2%)
## | | | [7] Age in (34,38], (38,45], (45,60]: No (n = 74, err = 8.1%)
## | | [8] YearsWithCurrManager in (1,2], (2,4], (4,7], (7,17]
## | | | [9] JobSatisfaction in Low: No (n = 124, err = 14.5%)
## | | | [10] JobSatisfaction in Medium, High, Very_High
## | | | | [11] BusinessTravel in Non-Travel, Travel_Rarely: No (n = 374, err = 4.0%)
## | | | | [12] BusinessTravel in Travel_Frequently: No (n = 84, err = 11.9%)
## | [13] OverTime in Yes
## | | [14] MaritalStatus in Divorced, Married
## | | | [15] JobLevel in 1
## | | | | [16] Age in [18,29]: Yes (n = 24, err = 37.5%)
## | | | | [17] Age in (29,34], (34,38], (38,45], (45,60]: No (n = 43, err = 23.3%)
## | | | [18] JobLevel in 2, 3, 4, 5
## | | | | [19] EnvironmentSatisfaction in Low, Medium: No (n = 48, err = 18.8%)
## | | | | [20] EnvironmentSatisfaction in High, Very_High: No (n = 86, err = 4.7%)
## | | [21] MaritalStatus in Single
## | | | [22] Age in [18,29], (29,34]
## | | | | [23] DistanceFromHome in [1,2], (2,5], (5,9]: Yes (n = 33, err = 39.4%)
## | | | | [24] DistanceFromHome in (9,17], (17,29]: Yes (n = 18, err = 0.0%)
## | | | [25] Age in (34,38], (38,45], (45,60]
## | | | | [26] JobSatisfaction in Low, Medium, High: No (n = 25, err = 48.0%)
## | | | | [27] JobSatisfaction in Very_High: No (n = 17, err = 5.9%)
##
## Number of inner nodes: 13
## Number of terminal nodes: 14confusionMatrix(chaid.m4)## Cross-Validated (10 fold) Confusion Matrix
##
## (entries are percentual average cell counts across resamples)
##
## Reference
## Prediction No Yes
## No 78.0 11.5
## Yes 5.9 4.7
##
## Accuracy (average) : 0.8262confusionMatrix(predict(chaid.m4), y)## Confusion Matrix and Statistics
##
## Reference
## Prediction No Yes
## No 835 101
## Yes 29 65
##
## Accuracy : 0.8738
## 95% CI : (0.8519, 0.8935)
## No Information Rate : 0.8388
## P-Value [Acc > NIR] : 0.0009858
##
## Kappa : 0.434
##
## Mcnemar's Test P-Value : 4.751e-10
##
## Sensitivity : 0.9664
## Specificity : 0.3916
## Pos Pred Value : 0.8921
## Neg Pred Value : 0.6915
## Prevalence : 0.8388
## Detection Rate : 0.8107
## Detection Prevalence : 0.9087
## Balanced Accuracy : 0.6790
##
## 'Positive' Class : No
## plot(chaid.m4)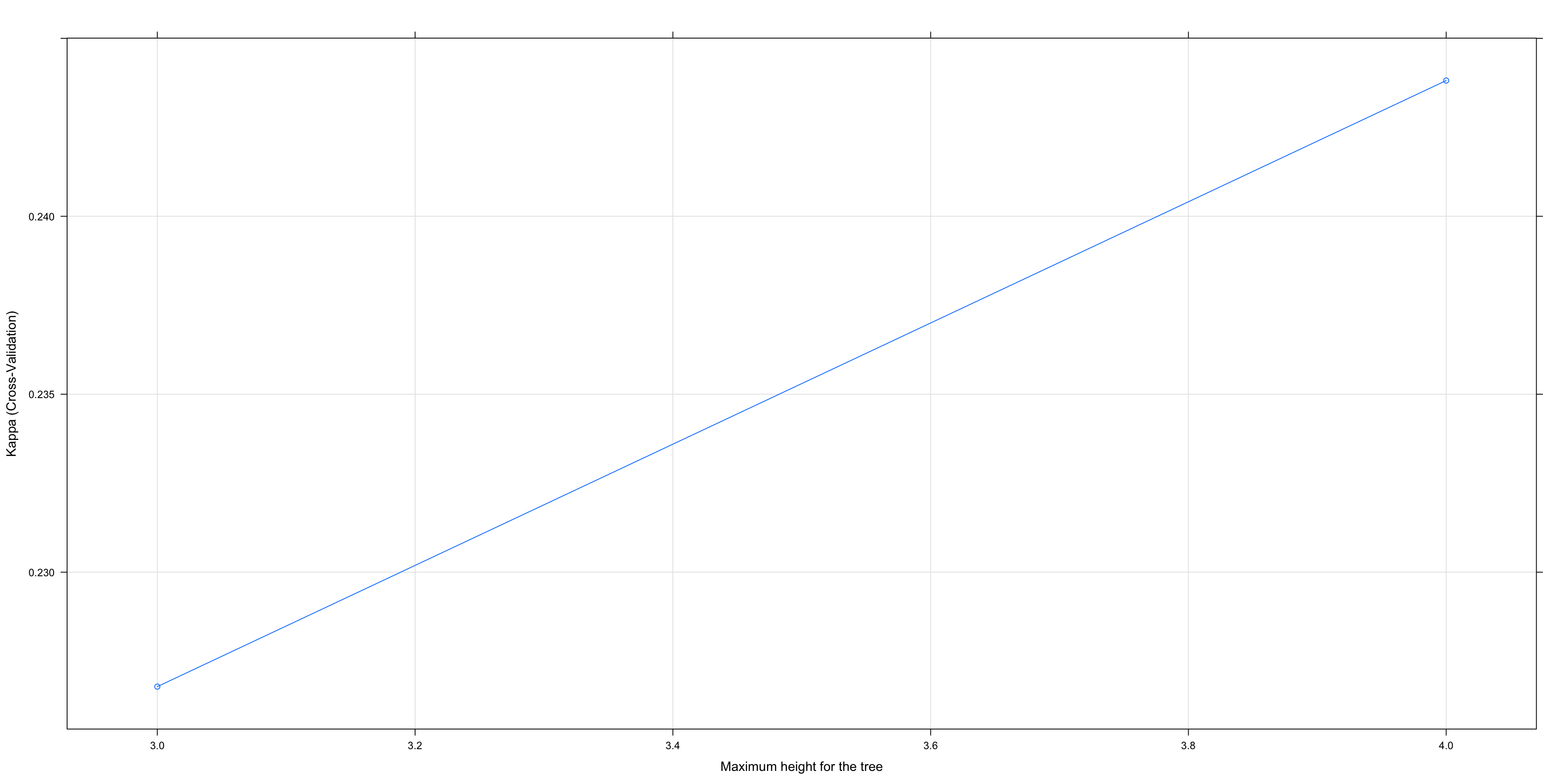
plot(chaid.m4$finalModel)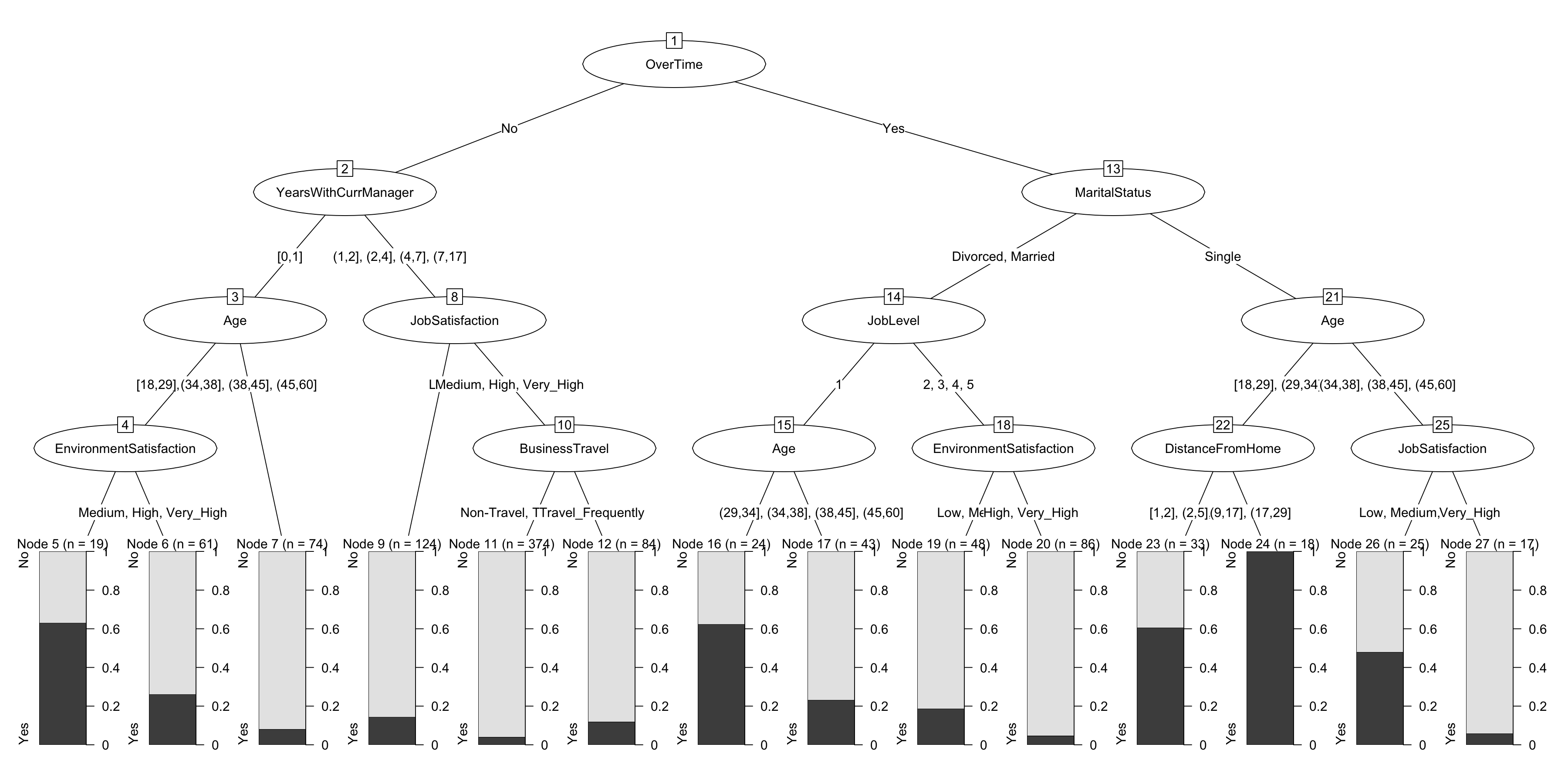
Although this post is more about explaining how to use the tools than it is about actually fitting this fictional data, let’s review all four of the models we built for comparative purposes. If you need to review what all these measures are please consult this webpage Confusion Matrix.
confusionMatrix(predict(chaid.m1, newdata = test), test$Attrition)## Confusion Matrix and Statistics
##
## Reference
## Prediction No Yes
## No 359 64
## Yes 10 7
##
## Accuracy : 0.8318
## 95% CI : (0.7935, 0.8656)
## No Information Rate : 0.8386
## P-Value [Acc > NIR] : 0.6791
##
## Kappa : 0.1032
##
## Mcnemar's Test P-Value : 7.223e-10
##
## Sensitivity : 0.97290
## Specificity : 0.09859
## Pos Pred Value : 0.84870
## Neg Pred Value : 0.41176
## Prevalence : 0.83864
## Detection Rate : 0.81591
## Detection Prevalence : 0.96136
## Balanced Accuracy : 0.53575
##
## 'Positive' Class : No
## confusionMatrix(predict(chaid.m2, newdata = test), test$Attrition)## Confusion Matrix and Statistics
##
## Reference
## Prediction No Yes
## No 344 53
## Yes 25 18
##
## Accuracy : 0.8227
## 95% CI : (0.7838, 0.8573)
## No Information Rate : 0.8386
## P-Value [Acc > NIR] : 0.834733
##
## Kappa : 0.221
##
## Mcnemar's Test P-Value : 0.002235
##
## Sensitivity : 0.9322
## Specificity : 0.2535
## Pos Pred Value : 0.8665
## Neg Pred Value : 0.4186
## Prevalence : 0.8386
## Detection Rate : 0.7818
## Detection Prevalence : 0.9023
## Balanced Accuracy : 0.5929
##
## 'Positive' Class : No
## confusionMatrix(predict(chaid.m3, newdata = test), test$Attrition)## Confusion Matrix and Statistics
##
## Reference
## Prediction No Yes
## No 348 56
## Yes 21 15
##
## Accuracy : 0.825
## 95% CI : (0.7862, 0.8594)
## No Information Rate : 0.8386
## P-Value [Acc > NIR] : 0.8014235
##
## Kappa : 0.1927
##
## Mcnemar's Test P-Value : 0.0001068
##
## Sensitivity : 0.9431
## Specificity : 0.2113
## Pos Pred Value : 0.8614
## Neg Pred Value : 0.4167
## Prevalence : 0.8386
## Detection Rate : 0.7909
## Detection Prevalence : 0.9182
## Balanced Accuracy : 0.5772
##
## 'Positive' Class : No
## confusionMatrix(predict(chaid.m4, newdata = test), test$Attrition)## Confusion Matrix and Statistics
##
## Reference
## Prediction No Yes
## No 348 56
## Yes 21 15
##
## Accuracy : 0.825
## 95% CI : (0.7862, 0.8594)
## No Information Rate : 0.8386
## P-Value [Acc > NIR] : 0.8014235
##
## Kappa : 0.1927
##
## Mcnemar's Test P-Value : 0.0001068
##
## Sensitivity : 0.9431
## Specificity : 0.2113
## Pos Pred Value : 0.8614
## Neg Pred Value : 0.4167
## Prevalence : 0.8386
## Detection Rate : 0.7909
## Detection Prevalence : 0.9182
## Balanced Accuracy : 0.5772
##
## 'Positive' Class : No
## At this juncture we’re faced with the same problem we had in my last post. We’re drowning in data from the individual confusionMatrix results. We’ll resort to the same purrr solution to give us a far more legible table of results focusing on the metrics I’m most interested in. To do that we need to:
- Make a
named listcalledmodellistthat contains our 4 models with a descriptive name for each - Use
mapfrompurrrto apply thepredictcommand to each model in turn to ourtestdataset - Pipe those results to a second
mapcommand to generate a confusion matrix comparing our predictions totest$Attritionwhich are the actual outcomes. - Pipe those results to a complex
map_dfr(that I explained last time) that creates a dataframe of all the results with each CHAID model as a row. - Show us the names of the columns we have available.
modellist <- list("Default tune" = chaid.m1,
"a2 & a4 stricter" = chaid.m2,
"Custom parameters" = chaid.m3,
"3 or 4 levels" = chaid.m4)
CHAIDResults <- map(modellist, ~ predict(.x, newdata = test)) %>%
map(~ confusionMatrix(test$Attrition, .x)) %>%
map_dfr(~ cbind(as.data.frame(t(.x$overall)),as.data.frame(t(.x$byClass))), .id = "ModelNumb")
names(CHAIDResults)## [1] "ModelNumb" "Accuracy" "Kappa"
## [4] "AccuracyLower" "AccuracyUpper" "AccuracyNull"
## [7] "AccuracyPValue" "McnemarPValue" "Sensitivity"
## [10] "Specificity" "Pos Pred Value" "Neg Pred Value"
## [13] "Precision" "Recall" "F1"
## [16] "Prevalence" "Detection Rate" "Detection Prevalence"
## [19] "Balanced Accuracy"From the list of available columns let’s use dplyr to select just the columns we want, round the numeric columns to 3 digits and then use kable to make a pretty table that is much easier to understand.
CHAIDResults %>%
select("ModelNumb", "Accuracy", "Kappa", "Sensitivity", "Specificity", "Neg Pred Value", "F1", "Balanced Accuracy") %>%
mutate_if(is.numeric,funs(round(.,3))) %>%
kable("html") %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| ModelNumb | Accuracy | Kappa | Sensitivity | Specificity | Neg Pred Value | F1 | Balanced Accuracy |
|---|---|---|---|---|---|---|---|
| Default tune | 0.832 | 0.103 | 0.849 | 0.412 | 0.099 | 0.907 | 0.630 |
| a2 & a4 stricter | 0.823 | 0.221 | 0.866 | 0.419 | 0.254 | 0.898 | 0.643 |
| Custom parameters | 0.825 | 0.193 | 0.861 | 0.417 | 0.211 | 0.900 | 0.639 |
| 3 or 4 levels | 0.825 | 0.193 | 0.861 | 0.417 | 0.211 | 0.900 | 0.639 |
By nearly every measure we care about, chaid.m2 (where the best fit was alpha2 = 0.05 and alpha4 = 0.001) clearly emerges as the best predictor against out test dataset. N.B. notice that if you only focus on the default accuracy measure, the models are all very close. But if you focus on more precise measures like Kappa and Negative Predictive Value (which in this case is a great indicator of how well we are specifically getting our prediction of attrition correct – compared to the more common case of predicting that people will stay)
It’s a very simple and parsimonious model, where we only need to know three things about the staff member to get pretty accurate predictions; Overtime, YearsAtCompany, and JobLevel. It’s very clear that some of the other variables may be at work here but we should acquire more data to make that assessment rather than trying to overpredict with the data we have on hand.
Done!
I hope you’ve found this useful. I am always open to comments, corrections and suggestions. Please feel free to email of drop a comment via disqus.
Chuck